[Stata] calculating segregation indices using seg and getcensus packages
Understanding the measures of segregation
If you are viewing this post, you may be interested in creating a segregation index. Representatively, racial segregation is well known, but we can create our own segregation indices for different factors, such as age, immigrant status, economic status, or ethnicity. Scholars have proposed and tested various ways to measure segregation in the past decades (See Sean & Firebaugh, 2002; Massey & Denton; 1998). Among them, the most popular ones are 1) dissimilarity index, 2) exposure index (between two groups), and 3) isolation index. To add a few, the Entropy Diversity Index and the Gini Segregation Index are also used. How are these measurements different, and how do they work in reality? I highly recommend this video produced by the Othering & Belonging Institute at UC Berkeley to understand.
United States Segregation Map by Othering & Belonging Institute

For a better understanding, you can find the mathematical explanation of the dissimilarity index here.
Here is a summary of the indices that are used frequently.
- Entropy Diversity Index: This index measures the degree of diversity in a geographical unit.
- The denominator is the total number of individuals in the geographical unit, and the numerator is the sum of the negative product of the proportion of each racial group and the log of that proportion.
- The index ranges from 0 to infinity, with 0 indicating that all individuals in the geographical unit belong to the same racial group, and higher values indicating greater diversity.
- Dissimilarity Index: This index measures the proportion of individuals from one racial group who would have to move to a different geographical unit in order for the racial distribution to be the same in both units. In other words, the percentage of the minority group’s population that would have to change residence for each neighborhood (in general, tract) to have the same percentage of that group.
- The denominator is the total number of individuals in each geographical unit, and the numerator is the sum of the absolute difference in the proportion of each racial group between the two geographical units.
- The index ranges from 0 to 1, with 0 indicating that the racial distribution is the same in both geographical units, and 1 indicating that the racial distribution is completely different.
- Isolation Index: The Isolation Index measures the “extent to which minority members are exposed only to one another.” (Massey and Denton, p. 288)
- The denominator is the total number of individuals in the geographical unit, and the numerator is the proportion of individuals in the racial group who live in the geographical unit divided by the proportion of the entire population in the geographical unit who are members of that racial group.
- A higher index value indicates greater isolation of a racial group in the geographical unit. The index can range from 0 to infinity, with values close to 0 indicating little to no isolation and values approaching infinity indicating complete isolation of a racial group in the geographical unit.
- (Two-group) Exposure Index: This index measures the degree to which two racial groups are exposed to each other in a geographical unit. (Originally: the degree of potential contact, or the possibility of interaction, between minority and majority group members (Massey and Denton, p. 287))
- The denominator is the total number of individuals in the geographical unit, and the numerator is the product of the proportion of each racial group and the absolute difference in the proportion of each racial group between the two geographical units.
- The index ranges from 0 to 1, with 0 indicating that the two racial groups are evenly distributed across all geographical units, and 1 indicating that one racial group is completely absent from geographical units where the other racial group is present.
- (Multi-group) Normalized Exposure Index: This index is similar to the (two-group) Exposure Index, but it measures the degree to which multiple racial groups are exposed to each other in a geographical unit.
- The denominator is the total number of individuals in the geographical unit, and the numerator is the sum of the product of the proportion of each racial group and the absolute difference in the proportion of each racial group between each pair of geographical units.
- The index ranges from 0 to 1, with 0 indicating that the racial groups are evenly distributed across all geographical units, and 1 indicating that one racial group is completely absent from geographical units where other racial groups are present.
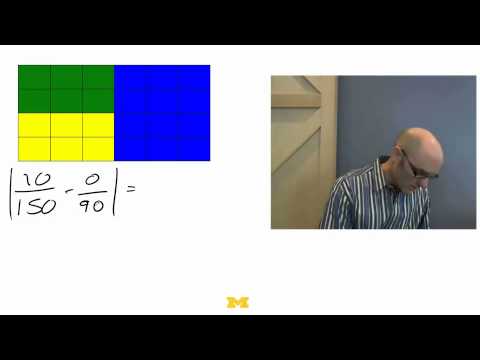
You can also find a more intuitive description of the difference between dissimilarity and interaction index in the following figure in DiNardi et al. (2022).

How to make your own segregation indices
All of these measurements are calculated with different formulas. Also, most variables are calculated as summary variables through data at a lower level (e.g., zip code or tract) than the larger unit (e.g., county) being calculated (Yes, you need the nested dataset to calculate segregation indices).
You can write the code for the formulas, but researchers who have already researched this topic have created many tools to make this handy. Stata has a seg command (developed by Dr. Reardon), R has a segregation and oasisR package, and Python has a segregation package in a PySAL library. There are recently developed packages for segregation indices in Stata: dseg and stregsmall, but this post will focus on seg package only.
Stata seg package
In this post, I would love to introduce Stata’s seg command. Here are the options and available indices to be calculated using the seg package. Before coding, let’s look at what indices can be created using this package. Below is a summary of the help output from the seg package.
For an understanding of the formulas, you should note the following things.
- Total count within the unit:
t=SUM(varlist) - Proportion of the unit within the category
n:qn = varn/SUM(varlist) g: group name (e.g., one race)
| Option | Description of the index | Interpretation | Formula | Output variable name |
|---|---|---|---|---|
| i | Normalized Simpson Interaction Diversity Index | [n/(n-1)]*SUM[qn * (1 – qn)] | Idiv | |
| e | Entropy Diversity Index* | Eu = SUM[qn * LOG(1/qn)] | Ediv | |
| d | Dissimilarity Index | 0 (no segregation) -1 (complete segregation) | Dg = SUMn[SUMu[t * |Qn – qn|]] / (2 * T * Ig) | Dseg |
| g | Gini Segregation Index | 0 (no segregation) -1 (complete segregation) | SUMn[SUMui[SUMuj[ti * tj * |qni – qnj|]]] / (2 * T * T * Ig) | Gseg |
| h | Theil Information Theory Index. The Theil Entropy Diversity Index is also calculated if this option is specified. | 0 (no segregation) -1 (complete segregation) | Hg = 1 – [SUM((t/T)*Eu) / Eg] | Hseg |
| c | Squared Coefficient of Variation Segregation Index | 0 (no segregation) -1 (complete segregation) | SUMn[SUMu[t * (Qn – qn) * (Qn – qn)] / [T * Qn * (M – 1)]] | Cseg |
| r | Relative Diversity Segregation Index | 0 (no segregation) -1 (complete segregation) | SUMn[SUMu[t * (Qn – qn) * (Qn – qn)] / (T * Ig)] | Rseg |
| s | Isolation Index for the group specified in var1. Other groups listed in varlist are included in the calculation of the index. | 0 (no isolation)-1 (complete isolation) | SUMu((t * q1 * q1) / (T * Q1)] | Sseg |
| x | (two‐group) Exposure Index. The calculated exposure is the exposure of the group specified in var1 to the group specified in var2. Groups listed in varlist are included in the calculation of the index. | 0 (no exposure) – 1 (complete exposure) | SUMu((t * q1 * q2) / (T * Q1)] | Xseg |
| n | (two‐group) Normalized Exposure Index. The calculated exposure is the exposure of the group specified in var1 to the group specified in var2. Groups listed in varlist are included in the calculation of the index. | 0 (no segregation) -1 (complete segregation) | 1 – Xg/Q2 | Nseg |
| p | (multi‐group) Normalized Exposure Index | 0 (no segregation) -1 (complete segregation) | SUMn[SUMu[t * (Qn – qn) * (Qn – qn)] / [T * (1 – Qn)]] | Pseg |
For your information, the scores from Idiv, Dseg, Gseg, Pseg, Sseg, and others are the same regardless of the order of the variable in the varlist but the scores from Xseg and Nseg depend on the order of the variables (e.g., varlists such as var1 var2 var3 var4 and var2 var1 var3 var4 show the different outcomes. Idiv is on the var1, so it also depends on the order of the variables. Almost all variables rely on the total counts in the varlist, so the number of variables in the varlist could change the computed indices.
*Note: Entropy Diversity Index is provided automatically without the option e in the current version of seg package. For another way of creating an entropy index, you can consider ineqdeco or rpme packages for entropy index.
Code Examples from the author
Let’s create a racial segregation index, the most representative segregation index. It’s surprisingly simple 🙂
ssc install seg // install seg package
** general syntax
seg var1 var2 var3 var4, x s n ... by(unit)
// if you do not specify the unit, the indices will be calculated for the entire dataset
seg white black hisp asian natam, x s n by(state)
// x: calculates the white‐black exposure index,
// s: calculates the white isolation index,
// n: calculates the normalized white‐black exposure index among all schools in the data.
// including all the racial/ethnic groups to count for the size of other groups.
seg white black, x s n
// If you do not put the data for other raial/ethnic groups,
// this syntax will calculate the exposure and isolation indices
// *ignoring* all students other than black and white students.Application with American Community Survey datasets
Let’s practice with American Community Survey (ACS) data. If you are not familiar with getcensus pacakge, you can read more about how to load ACS data from Stata in the following post.
▶️[Stata] getcensus package for American Community Survey datasets
Here, my objective is to calculate the dissimilarity and exposure index for Asians and Hispanics in New York State.
* Load census-tract based population size of racial/ethnic groups in NYS (statefips is 36)
** these tables are under B03002 to have four groups: non-hispanic white / black / asian and hispanic populations.
getcensus B03002_004 B03002_006 B03002_003 B03002_012, year(2021) sample(5) geography(tract) statefips(36) clear
* rename variables (You can skip this step, but I recommend it)
rename b03002_004e black
rename b03002_006e asian
rename b03002_003e white
rename b03002_012e hispanic
* calculate segregation indices
** g: Gini Segregation Index
** s: isolation index for Asian
** x: two-group exposure index for Asian and Hispanic exposure
** popcoutns: bias-correction for the population counts
seg asian hispanic black white, g s x by(county) popcounts file(outfile.dta) replace
* two-group dissimilarity index
** To calculate two-group dissimilarity index, you need to put only two groups.
seg asian hispanic, d by(county) popcounts file(outfile2.dta) replaceIf you open the outfile.dta file, you can see the indices calculated at the county level. Xseg is the exposure index for Asian – Hispanic exposure. Considering the county fips, Asian living in NYS have high probability of being exposed to Hispanic populations in Bronx county (36005), Montgomery county (36057), Queens county (36081), and Westchester County (36119). For your information, the variable nunits means the number of census tracts.

More references
US Census. Housing Patterns: Appendix B: Measures of Residential Segregation
