[Mplus] Introduction to Latent Class Analysis and Useful References
In social sciences, the research used to identify the typology and clusters allows for better targeting the vulnerable populations or distinct types. In the past, the K-means clustering method was popular for this purpose, but latent class/latent profile analysis is getting popular as an alternative method to find the cluster based on a person-centered approach rather than a variable-based approach. The basic concept of LCA is individuals (=cases) could be subdivided into classes (=subgroups) based on the unobservable construct (=indicators).
Latent class analysis

- latent profile analysis (with continuous indicators) / latent class analysis (with categorical indicators)
- Also known as: Mixture Likelihood Approach clustering, Model-based clustering, and Mixture-Model clustering.
- Only available in cross-sectional studies. There are other typology methods for longitudinal studies (e.g., latent growth class analysis).
- Difference from K-means clustering method: LCA is a method that overcomes the limitations of cluster analysis in several ways. The following study articulates it well and straightforwardly in the Summary and Conclusion section.
- Magidson, J., & Vermunt, J. (2002). Latent class models for clustering: A comparison with K-means. Canadian Journal of Marketing Research, 20(1), 36-43.
- Here is an example of LCA results with three classes.

3-step approach
What is the 3-step approach?

- Step 1: estimating a standard LC model without covariates
- Step 2: assigning subjects to latent classes
- Step 3: estimating a logistic regression model for the latent classes (multinomial logistic regression model)
Ref: Vermunt, J.K. (2010). Latent class modeling with covariates: Two improved three-step approaches. Political Analysis, 18, 450-469.
Please find the introduction to the 3-step approach in this video (first 23 minutes).
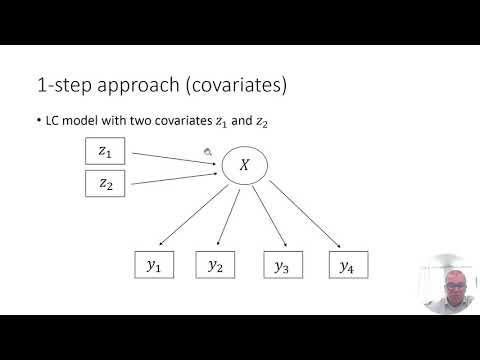
A three-step approach is a developing method! There is an active discussion on how to apply 3-step better with a variety of methods, including propensity score matching. Check this out if you want to learn more about it: A new three-step method for using inverse propensity weighting with latent class analysis | SpringerLink
Further, latent class analysis can include both covariates and distal outcomes. Please find the attached example.

Useful Links
- Geiser, C. (2012). Data analysis with Mplus. Guilford Press : One of the few textbooks covering latent class analysis as a separate chapter
- YouTube Lecture Videos

- Textbook Examples Applied Latent Class Analysis (ucla.edu): You can find the syntax for Mplus.
Further Readings
1. So, how person-centered approach is different from the variable-based approach? Is it better or worse? The answer is “they are complementary.” You may find the following reading helpful to learn about it!
2. This article also summarizes the potential application of LCA in development research. It is quite an extensive article, including the recent development of the method. Highly recommend!
Lanza, S. T., & Cooper, B. R. (2016). Latent class analysis for developmental research. Child Development Perspectives, 10(1), 59-64.
3. This article summarized the best practice of latent class analysis. This article is interesting in that it notes the limitation of LCA.
Researchers usually assign names to the identified classes and, because of the complexity of the classes, may advertently engage in “naming fallacy,” wherein the name of the class does not accurately reflect the class membership.
Weller, B. E., Bowen, N. K., & Faubert, S. J. (2020). Latent class analysis: a guide to best practice. Journal of Black Psychology, 46(4), 287-311.
Differences between machine learning-based clustering approaches and Latent Class analysis based approach
The latent class analysis is one of the clustering methods, and most other clustering methods are based on the machine learning approach. You can learn more about how the results of the clustering method could differ by reading this article.

Machine learning-based clustering is an unsupervised learning method that divides data into groups with similar characteristics. Latent profile analysis is a categorical latent variable modeling approach that divides data into latent subgroups.
The main differences between the two methods are:
- Machine learning-based clustering does not make any assumptions about the data distribution.
- The latent class analysis assumes the data was generated using a specific probabilistic model.
- Machine learning-based clustering assigns each data point to one cluster.
- The latent class analysis estimates the probability of each data point belonging to multiple subgroups.
- Machine learning-based clustering requires specifying the number of clusters in advance or using rules or indicators to find the optimal number.
- Latent class analysis can use model selection criteria or information criteria to determine the appropriate number of subgroups.
It depends on the research questions to determine which method is better. For example,
- Machine learning-based clustering can reflect the complexity and diversity of the data well and is easy to apply to new data. Latent class analysis may cause errors if the model assumptions do not fit and require additional steps to apply to new data.
- Latent class analysis can clearly explain the differences and similarities between subgroups and analyze the relationships or influences between variables. Machine learning-based clustering may lack meaning or interpretability between clusters and have difficulty identifying causal relationships between variables.

1 Response
[…] [Mplus] Introduction to Latent Class Analysis and Useful References […]