[Python] Collecting Reddit Datasets using Pushshift API
Why Pushshift API over the Reddit official API (PRAW)?
The Reddit API (PRAW) provides access to real-time data and allows you to interact with Reddit. PRAW is great for submitting posts or comments, messaging other users, or retrieving information about specific subreddits (for business purposes).
Pushshift, on the other hand, is an archival and search API that provides access to Reddit data in bulk. This means you can retrieve large amounts of historical data from Reddit, which is not easily possible with PRAW. Additionally, Pushshift allows you to search through Reddit content in ways that are not possible with PRAW. For example, Pushshift allows you to search for comments or posts based on specific keywords or within specific time ranges.
In summary, if you need access to large amounts of historical data or want to perform more advanced searches, Pushshift is likely the better choice, which applies to social scientists. To answer this question, please find these resources for more information.
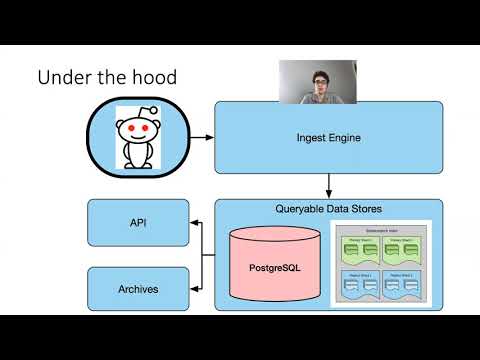
- New to Pushshift? Read this! FAQ : pushshift (reddit.com)
- [GitHub] Introduction to Reddit Data for Social Scientists
Import packages
from psaw import PushshiftAPI
from datetime import datetime as dt
import pandas as pd
pd.set_option('max_colwidth', 500)
pd.set_option('max_columns', 50)
api = PushshiftAPI(rate_limit_per_minute=60) PSAW is no longer updated; the creator recommends using PMAW instead. However, you can still use this code by adding (rate_limit_per_minute=60). If you want to collect data at a faster rate, write your code using PMAW.
Collecting submissions by subreddit for specific dates
start_epoch=int(dt(2020, 3, 1).timestamp()) #start_date
end_epoch=int(dt(2021, 2, 28).timestamp()) #end_date
while start_epoch < end_epoch + 86200:
api_request_generator = api.search_submissions(subreddit='Subreddit name', after = start_epoch, before = start_epoch + 862000)
# You can change the name of the Subreddit
# 86200 * n // n = duration of collection (here, duration is 10 days)
aita_submissions = pd.DataFrame([submission.d_ for submission in api_request_generator])
aita_submissions['date'] = pd.to_datetime(aita_submissions['created_utc'], utc=True, unit='s')
aita_central = aita_submissions[['author', 'date', 'title', 'selftext', 'permalink', 'subreddit', 'score', 'num_comments', 'num_crossposts']]
start_date = dt.fromtimestamp(start_epoch)
dateStr = start_date.strftime("%Y %b %d")
print(dateStr)
aita_central.to_csv(r"C:\Users\Y\Reddit\Term 2\sub_" + dateStr + ".csv", index = False, header = True)
start_epoch += 860000 # 86000 * duration of collectionCollecting comments by subreddit for specific dates
start_epoch=int(dt(2020, 3, 1).timestamp()) #start_date
end_epoch=int(dt(2021, 2, 28).timestamp()) #end_date
while start_epoch < end_epoch + 86200:
api_request_generator = api.search_comments(subreddit='Subreddit name',
after = start_epoch, before = start_epoch + 860000)
# You can change the name of the Subreddit
# 86200 * n // n = duration of collection (here, duration is 10 days)
missy_comments = pd.DataFrame([comment.d_ for comment in api_request_generator])
missy_comments['date'] = pd.to_datetime(missy_comments['created_utc'], utc=True, unit='s')
missy_central = missy_comments[['author','date','subreddit','score','body','permalink']]
start_date = dt.fromtimestamp(start_epoch)
dateStr = start_date.strftime("%Y %b %d")
print(dateStr)
missy_central.to_csv(r"C:\Users\Y\Reddit\Term 2\com_" + dateStr + ".csv", index = False, header = True)
start_epoch += 860000 # 86000 * duration of collectionMerge CSV files
import os
import glob
import pandas as pd
os.chdir("file path")
extension = 'csv'
all_filenames = [i for i in glob.glob('*.{}'.format(extension))]
#combine all files in the list
combined_csv = pd.concat([pd.read_csv(f) for f in all_filenames ])
#export to csv
combined_csv.to_csv( "combined_csv.csv", index=False, encoding='utf-8-sig') References
pushshift/api: Pushshift API (github.com)
nlp-reddit-analysis/pushshift.py at master · amiekong/nlp-reddit-analysis (github.com)
